Every claim, traced to its source
General-purpose AI hallucinates. We built Ligant.ai so it can’t. Every number, every claim, every recommendation is anchored in a primary source. Every evidence we generate can be validated. Our goal is to reduce hallucination to zero, and every step we take is in service of that.
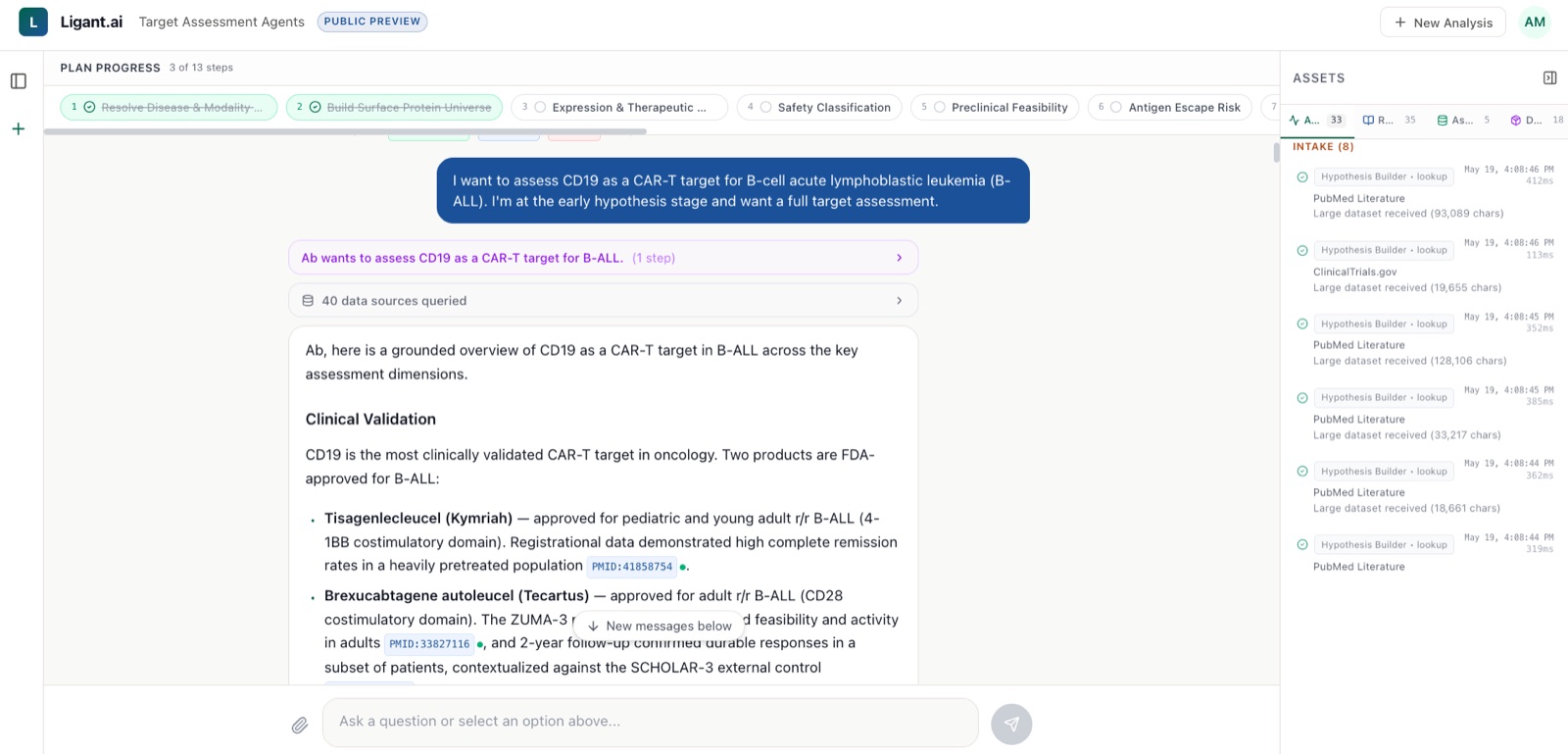
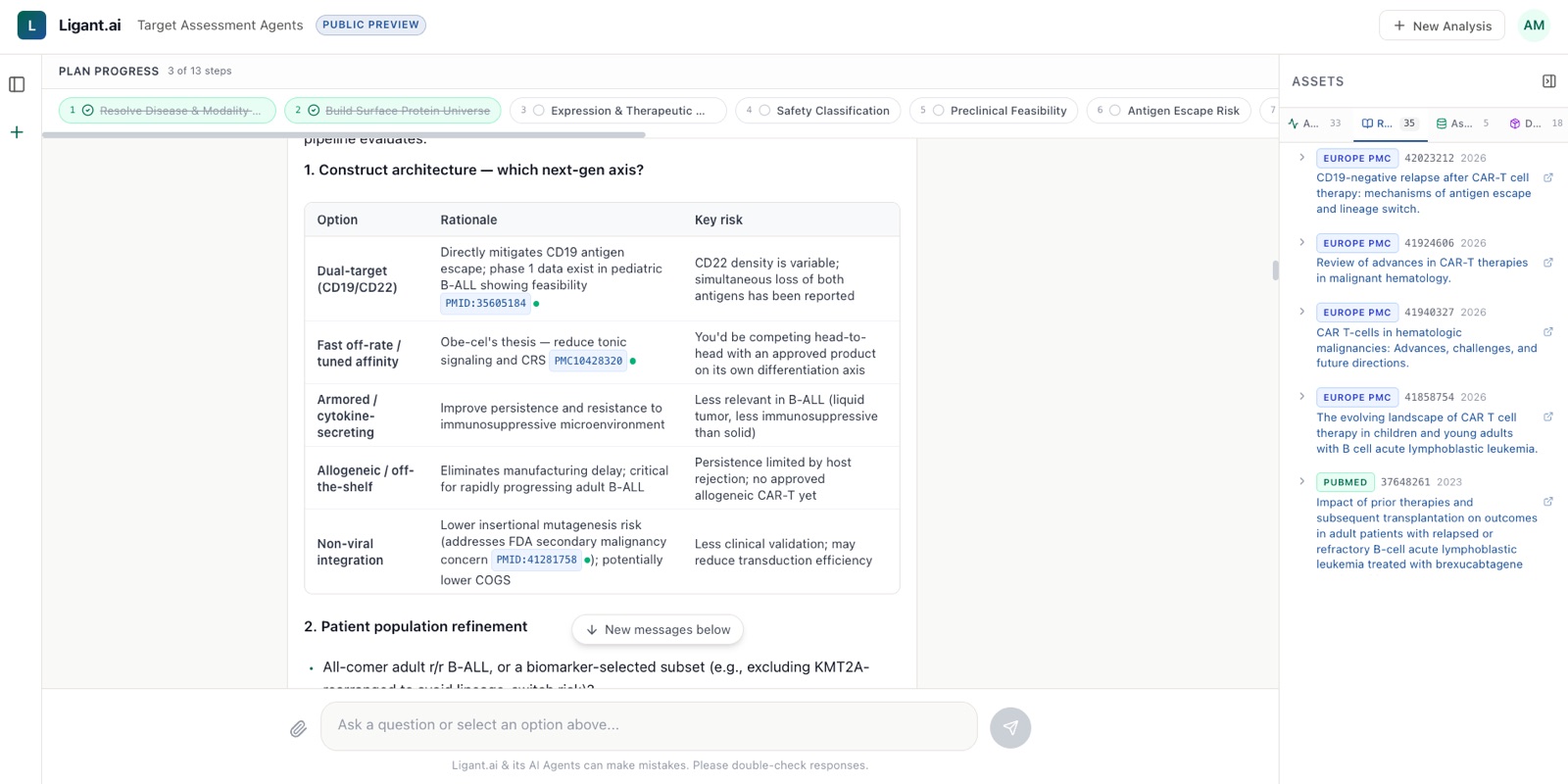
Comparison tables, fully sourced
When the platform compares construct architectures, patient populations, or competitor strategies, every cell is backed by a citation. No paraphrased summaries divorced from their origin.
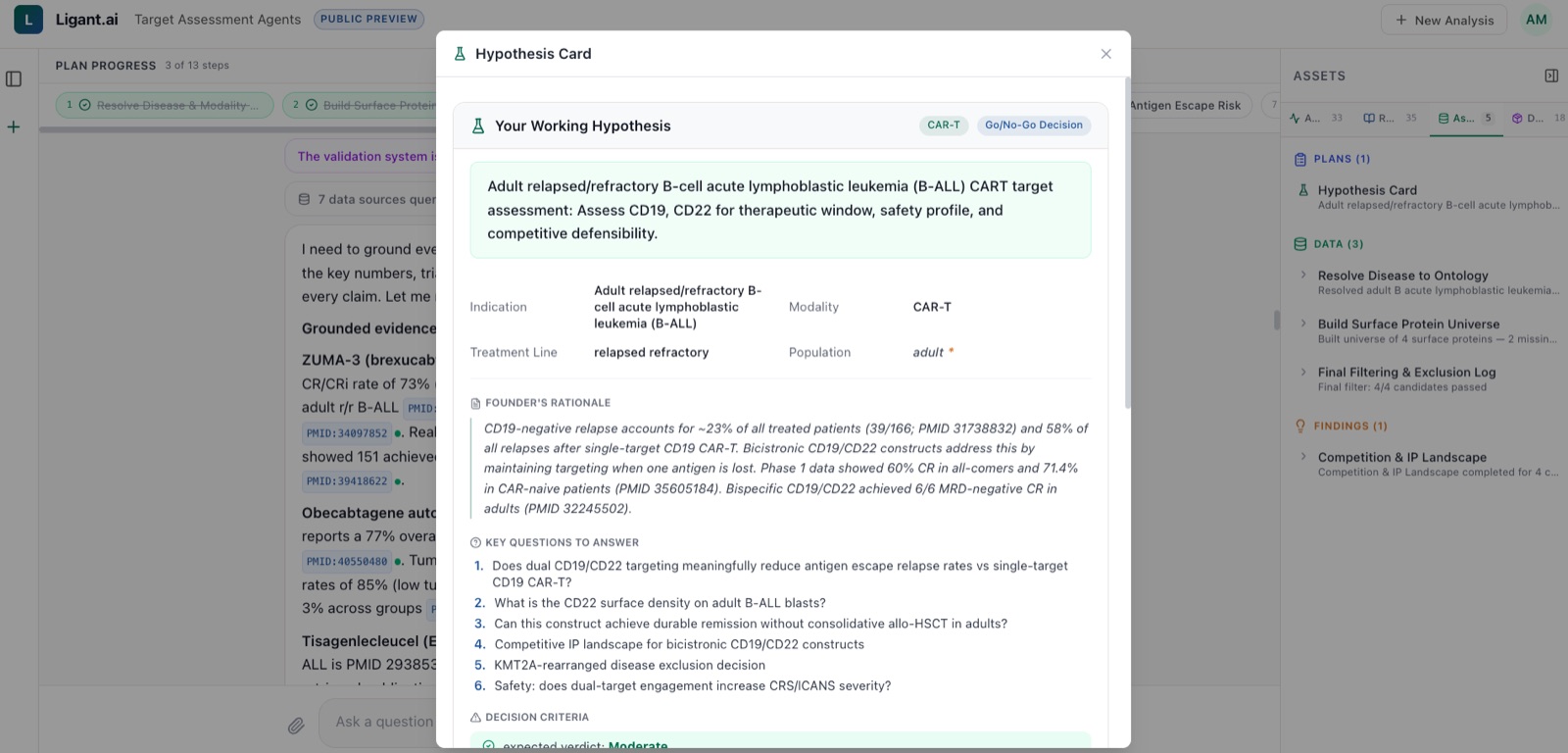
Your hypothesis, anchored in literature
Hypothesis cards capture indication, modality, treatment line, and founder rationale, with every claim cited, every assumption marked. Inferred fields are called out explicitly so nothing slips through unchecked.
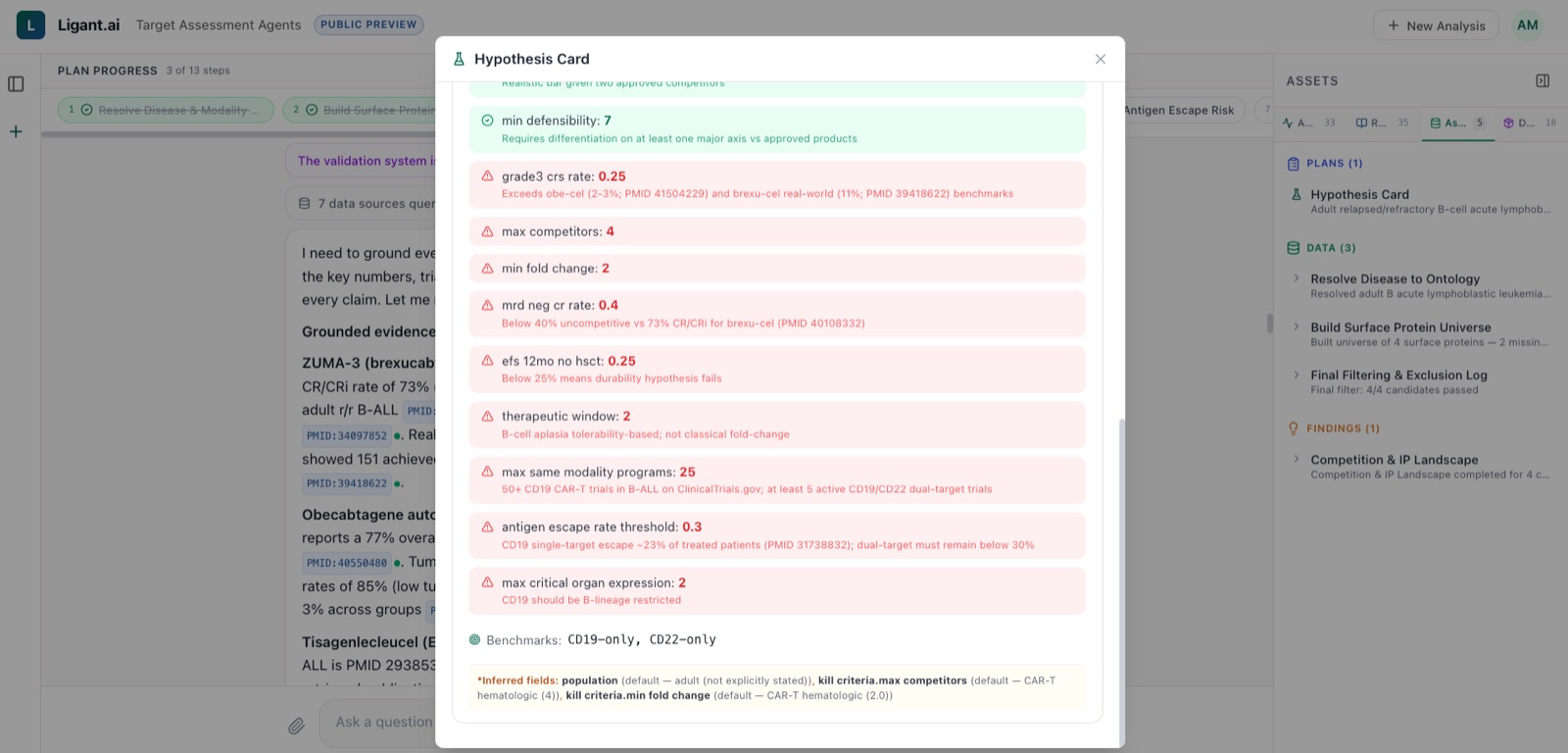
Decision thresholds, with their benchmarks
Every kill criterion (safety threshold, efficacy floor, competitive cutoff) is published alongside the benchmark it was derived from. You can audit, contest, or override any value before a gate decision is final.
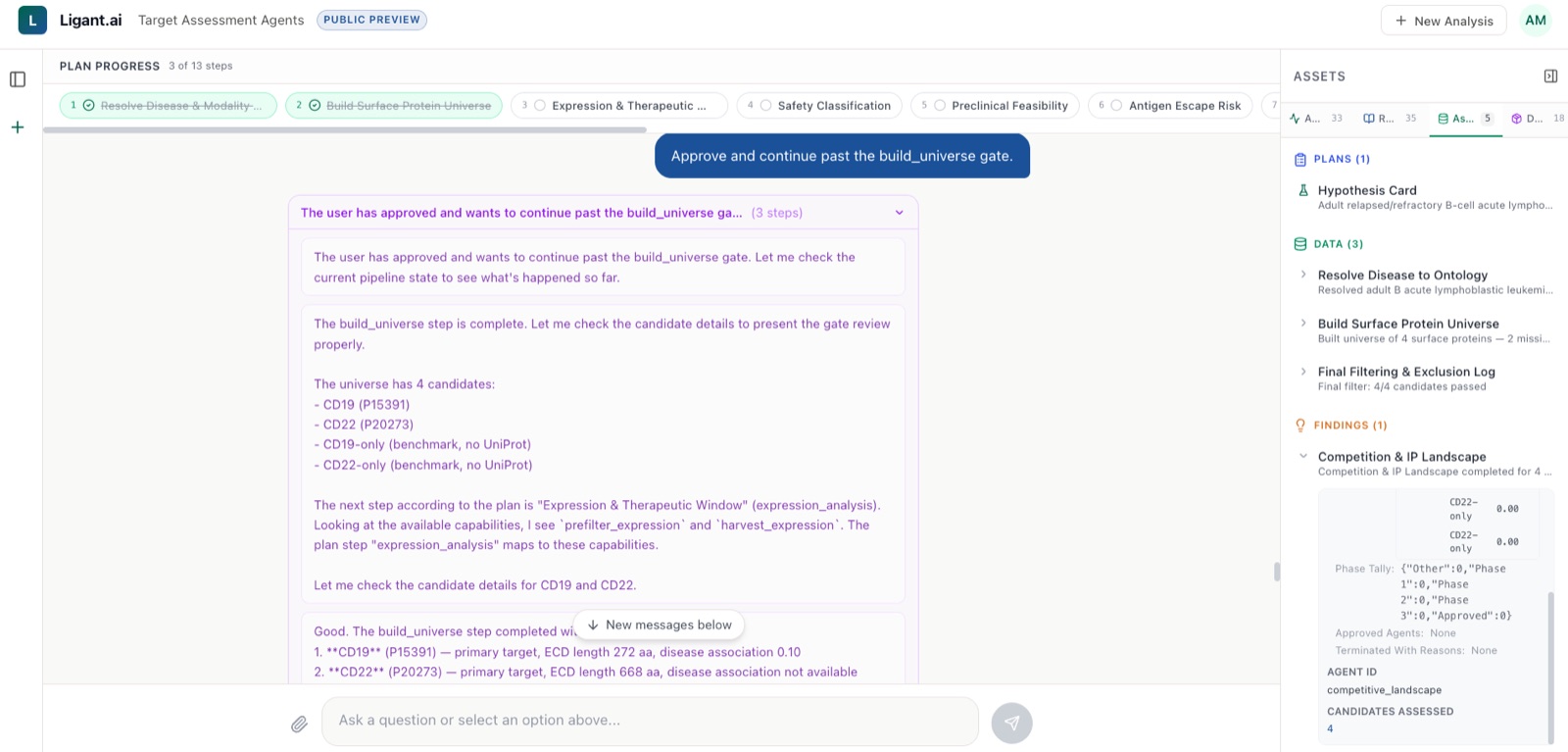
Agent reasoning, visible end-to-end
Watch each agent plan, query, and synthesize in real time. Every intake, retrieval, and decision is logged into the Assets panel, a complete audit trail you can replay, share with collaborators, or hand to a regulator.
Zero hallucination is the destination, not the claim. No system gets to zero on day one. What we promise is the audit trail to detect it, the citation infrastructure to challenge it, and a roadmap that prioritizes accuracy over speed at every gate.
Want to see it on your own target?
Start free with 500 credits500 free credits to get started. No credit card, no waitlist.
